沃顿商学院已发布4篇「Prompt」报告|重磅
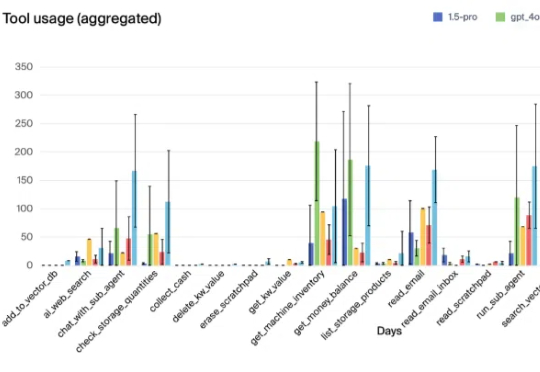
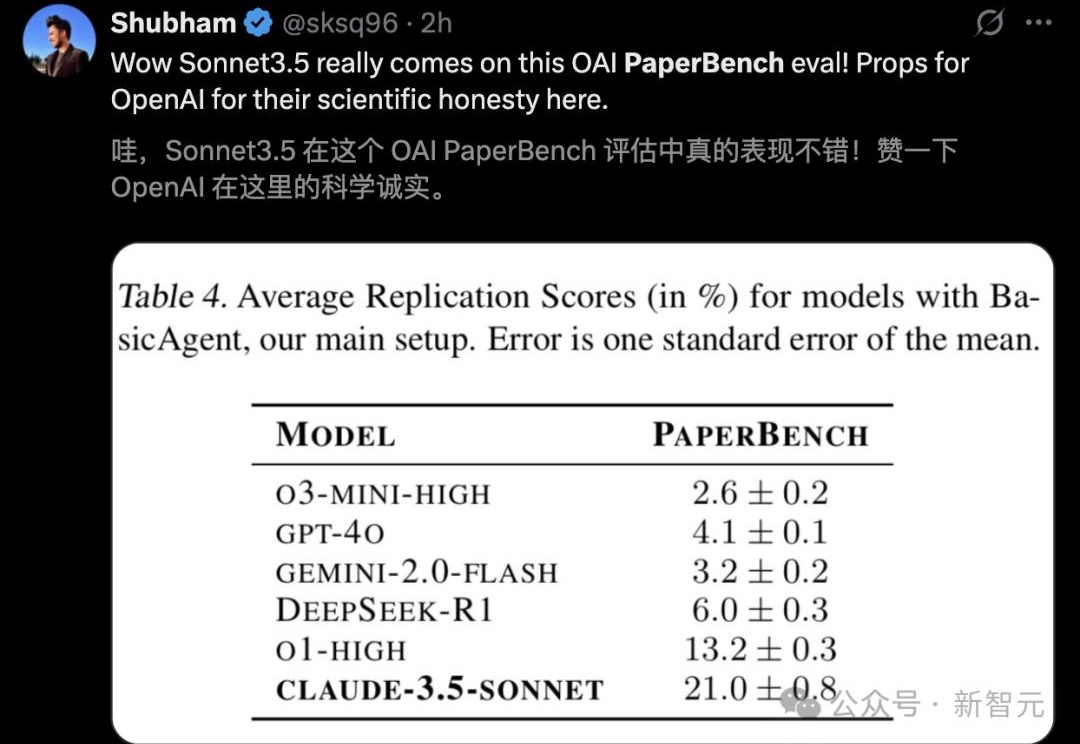
沃顿商学院已发布4篇「Prompt」报告|重磅宾夕法尼亚大学沃顿商学院(The Wharton School)今年发布了一系列名为《Prompting Science Reports》的重磅研究报告。他们选取了2024-2025最常用的模型(如GPT-4o, Claude 3.5 Sonnet, Gemini Pro/Flash等),在极高难度的博士级基准测试(GPQA Diamond)上进行了数万次的严谨测试。
来自主题: AI技术研报
9624 点击 2025-12-10 16:11